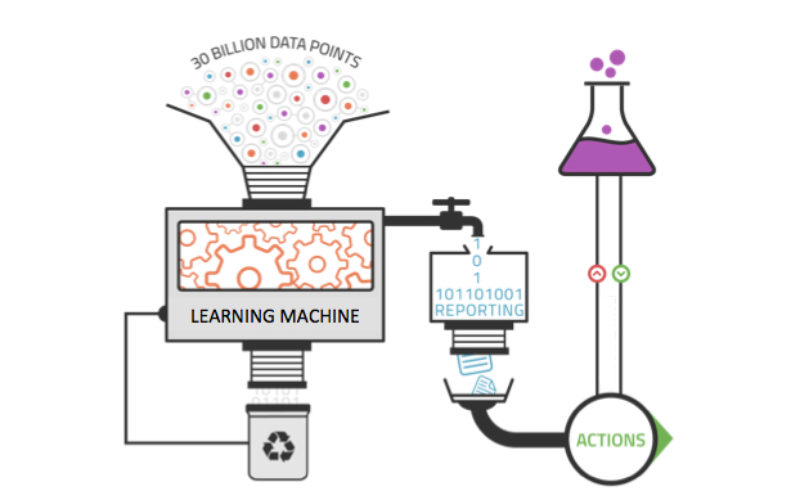
La inmensa acumulación de datos enfrentó al mundo con la problemática del volumen de información en cantidades nunca antes vistas. Así nació el Big Data, como una solución para capturar, gestionar, procesar y analizar combinaciones de conjuntos de datos cuyo tamaño (volumen), complejidad (variabilidad) y velocidad de crecimiento (velocidad) no pueden ser manejadas por herramientas tradicionales tales como bases de datos relacionales y estadísticas convencionales o paquetes de visualización dentro del tiempo necesario para que sean útiles.
Se estima que si toda la información producida por los seres humanos en el mundo se guardara en CDs se formaría una montaña tan alta que llegaría desde la Tierra hasta la Luna y volvería. En este contexto, entender qué es Big Data y la importancia que su correcta gestión produce en las empresas se convierte en un hito central para el crecimiento del revenue en los balances de negocio. La creación y almacenamiento masivo de datos no es exclusiva de una industria ni tampoco de los seres humanos. Las compañías privadas de diversos sectores, e incluso el sector público, mantienen grandes cantidades de datos transaccionales reuniendo información sobre clientes, proveedores y operaciones, datos de censo de población, registros médicos, impuestos, transacciones financieras realizadas en línea o por dispositivos móviles, análisis de redes sociales y ubicación geográfica mediante coordenadas GPS, por mencionar algunas.
En la Argentina, una de las primeras industrias en las que la explosión de información disponible vivió las consecuencias de buscar una aguja en un pajar fueron las compañías telefónicas con los análisis de los CDR (Call Detail Record), es decir, todos los datos que genera cada línea de celular. Cuando, por ejemplo, un edicto judicial pedía el historial de una línea, implicaba un reporte que se tenía que sacar de un repositorio de CDRs en los que se tenía que consultar registro por registro hasta recuperar todo lo solicitado. Esta actividad llevaba muchísimo tiempo e involucraba aún más recursos. Por lo que hubo que encontrar una solución eficiente. Esta solución vino de la mano de aplicar técnicas de Big Data como almacenamiento de datos distribuidos y algoritmos de map-reduce para el recupero de los datos.
El siguiente nivel en manejo de volúmenes de datos consistirá en contar con la capacidad de predecir la conducta. Machine Learning, disciplina científica del ámbito de la Inteligencia Artificial, crea sistemas que aprenden automáticamente, lo que significa identificar patrones complejos en millones de datos. En pocas palabras, con Machine Learning las organizaciones pasarán de ser reactivas a proactivas. Por ejemplo, podrían utilizarse este tipo de técnicas para hacer un análisis previo de las tomografías para que un sistema informático le indique al radiólogo cuales imágenes merecen particular atención en función de la presencia de anomalías.
En Semperti, con el objeto de acompañar a nuestros clientes en la transformación digital de sus negocios, hemos formado una práctica profesional en Big Data para ayudar a las empresas a integrar grandes volúmenes de datos, adquirir nuevas habilidades tecnológicas y vincular los silos de información para que puedan gestionar complejas transformaciones de datos garantizando la entrega de información de valor para el negocio en tiempo real.
Por María Elena Barros, presidente de Semperti.